
Atrinet Tech Blog Series.
ServiceNow MID Server Best Practices
If you work with ServiceNow Discovery or integrations long enough, you eventually hear the same sentence: “The MID Server is up, but nothing is working.”
That moment usually triggers log hunting, credential resets, and finger-pointing. In reality, most MID Server failures are not random. They are the predictable result of how the MID was designed, owned, and operated.
The MID Server is not just a job runner. It is the production bridge between your network and the ServiceNow platform. Treating it as anything less almost guarantees outages.
Treat the MID Server as production infrastructure
A MID Server needs the same discipline as any production system. Use a hardened OS baseline, define patching and upgrade policies, and apply antivirus exclusions that do not break Java or MID processes. Ownership must be explicit. Someone owns uptime, someone monitors health, and someone approves changes. Lifecycle planning matters too. You need an upgrade cadence and a rollback path. If nobody owns the MID, the MID will eventually own your delivery timeline.
Right-size and isolate by purpose
“One MID for everything” is a design smell. Discovery and integrations behave very differently and should not always share resources. High-volume integrations such as heavy API polling or event ingestion deserve dedicated MIDs. In segmented networks, deploy MIDs per zone instead of opening broad firewall rules. Isolation reduces blast radius and makes failures easier to reason about.
Network access and credentials are design decisions
Most “credential issues” are not credential problems. They are connectivity, DNS, or TLS problems in disguise. Before go-live, confirm required ports, proxy paths, DNS resolution consistency, NAT behavior, NTP sync, and TLS inspection policies. Credentials should follow a clear strategy. Use service accounts, least privilege, defined rotation, and match credential types to access methods such as WinRM, WMI, SSH, or APIs. When Windows Discovery coverage is low, the fix is often credential hygiene and WinRM readiness, not more scanning.
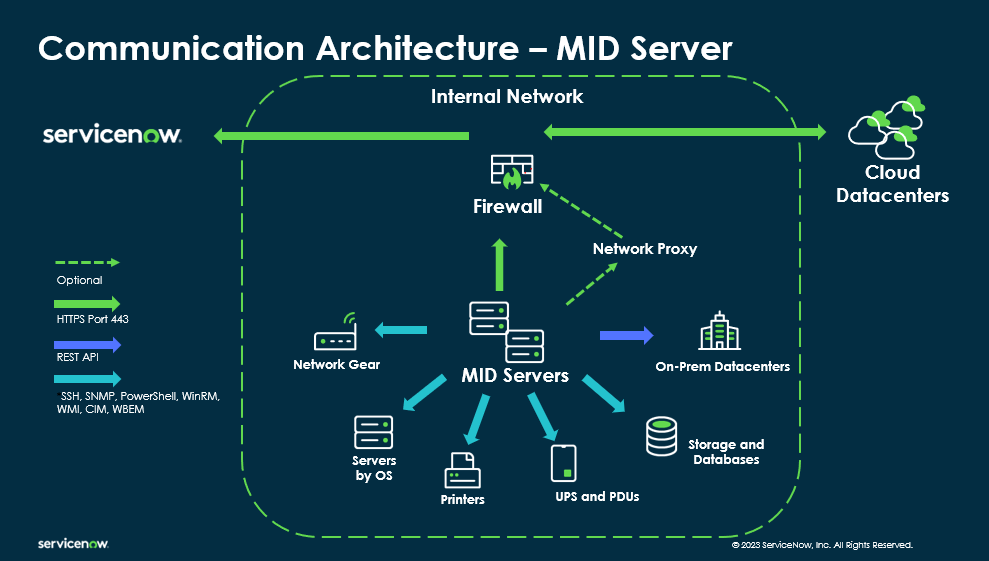
Scale using pools, not single nodes
Production environments should assume concurrency. Use multiple MIDs per capability and define selection rules so jobs distribute evenly. Monitor queue depth and execution time. A growing backlog is one of the earliest signals of trouble. A MID can appear healthy while work silently piles up behind it.
Observe the MID like an application
Heartbeat alone is meaningless. Track queue backlog, execution latency, error rates by pattern, and JVM heap trends over time. Certificate and TLS errors deserve special attention because they often appear after unrelated security changes. A MID that looks up can still be effectively down if it is drowning in backlog or stalled on downstream calls.
Expect change to break the MID first
Java updates, TLS policy hardening, proxy changes, firewall rule cleanup, and certificate rotation often break MIDs before anything else. Treat the MID as a canary. After any infrastructure or security change, run a simple smoke test that validates connectivity, execution, and data flow.
Build integrations for failure, not hope
For integrations that rely on MIDs, failure is normal. Implement retries with backoff, ensure idempotency to prevent duplicates, log correlation IDs for traceability, and maintain replay mechanisms for missed windows. This turns short outages into recoverable events instead of incidents.
Document a first-response playbook
When something fails, teams should know where to check logs first, how to validate connectivity quickly, and how to distinguish ServiceNow-side issues from source-side problems. This alone can cut mean time to recovery dramatically.
Keep dev, test, and prod aligned
Run the MID Servers for dev, test, and prod on the same host, with logical separation per instance. This minimizes environment drift. When network, DNS, Java, and certificates behave the same, testing becomes meaningful. If something breaks in prod, you debug configuration, not infrastructure.
When all else fails, phone a friend who’s done this before
If your MID Servers keep misbehaving, Discovery feels fragile, or every security change turns into a fire drill, it is usually not bad luck. It is architecture. This is where experienced ServiceNow integrators earn their keep. Teams like Atrinet have seen these exact failure patterns many times, know where to look first, and fix root causes instead of symptoms. Sometimes the smartest MID Server optimization is knowing when to call someone who has already made the mistakes for you.
MID Server failures are rarely mysterious. With ownership, isolation, observability, and resilience, they become predictable and preventable.
By: Shira Avissar
Full Stack & ServiceNow Developer
LinkedIn




















